Welcome to Ganymede
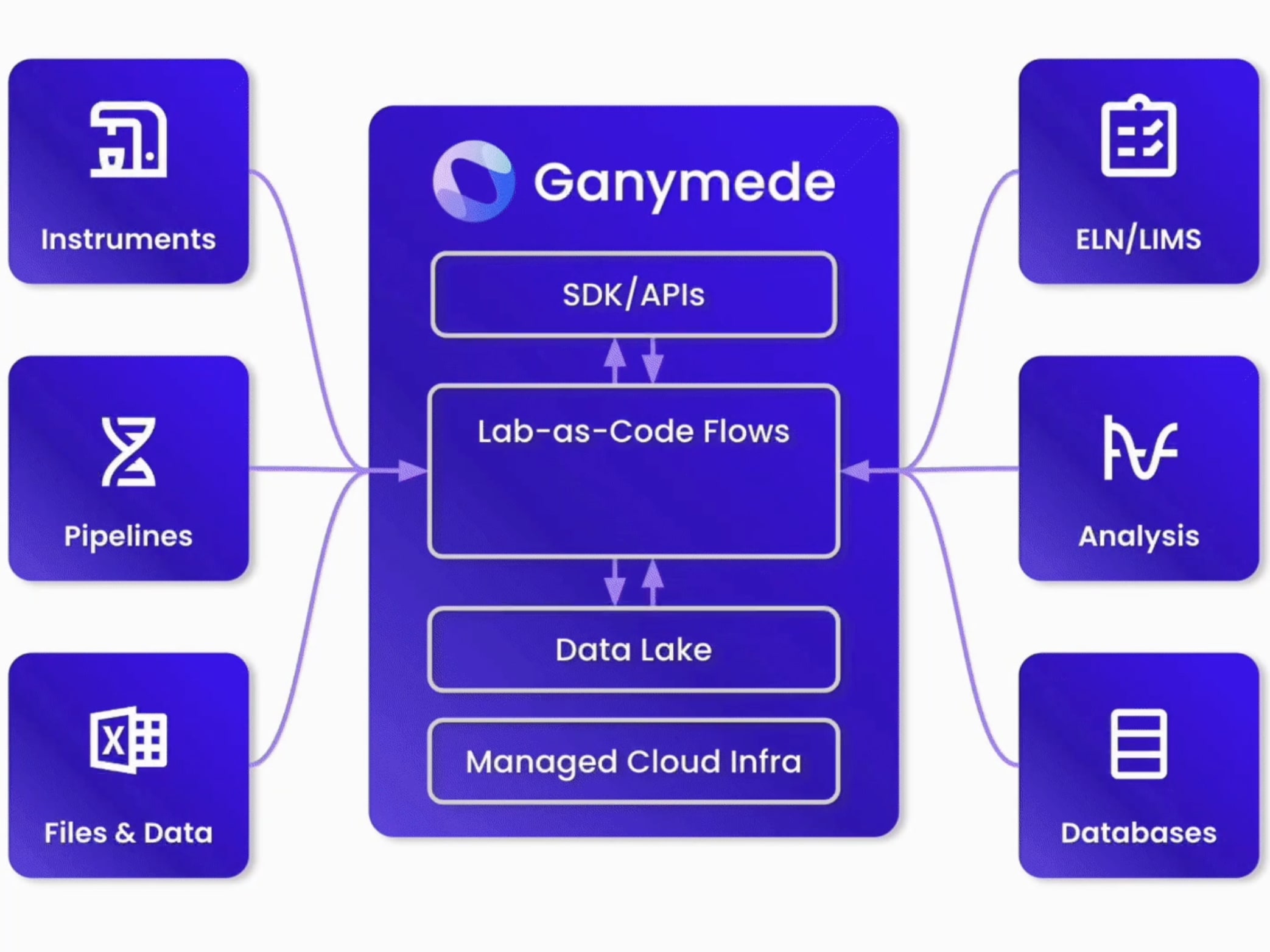
Ganymede is a cloud-based data platform, engineered to streamline the capture and processing of data between lab instruments, ELN/LIMS/analytical applications, and cloud platforms.
IT and Software Engineers use Ganymede to coordinate their data processing needs, eliminating the need to set up bespoke cloud infrastructure for hosting and executing code.
Process Engineers and Operations personnel leverage Ganymede to monitor process weaknesses and address bottlenecks.
Scientists rely on Ganymede to trace data generated from various sources. The platform consolidates critical data into one accessible location and processes it through shared pipelines to ensure reliability and accuracy in data capture and analysis.
Executive Leaders gain valuable insights from data-driven dashboards, facilitating transparent, informed planning and resource allocation decisions.
Some common use cases for Ganymede are:
Asset Utilization / Reliability Analysis: Monitoring instrument usage and performance over time to identify trends and potential issues.
Multilingual Connectivity: Providing a common platform to ensure that sample data, raw instrument output, and analyses travel together and are accessible in one place.
Platform Data Processing: Ensuring that shared data processing is executed in a consistent and secure environment with visibility for process owners.
Ganymede Components
The Ganymede Platform consists of a set of flexible, interchangeable components that enable data acquisition, processing, observation, and delivery to other systems.
Modular Analysis
Modular Analysis enables interactive web applications to be developed in Python notebooks and deployed to users in Ganymede.
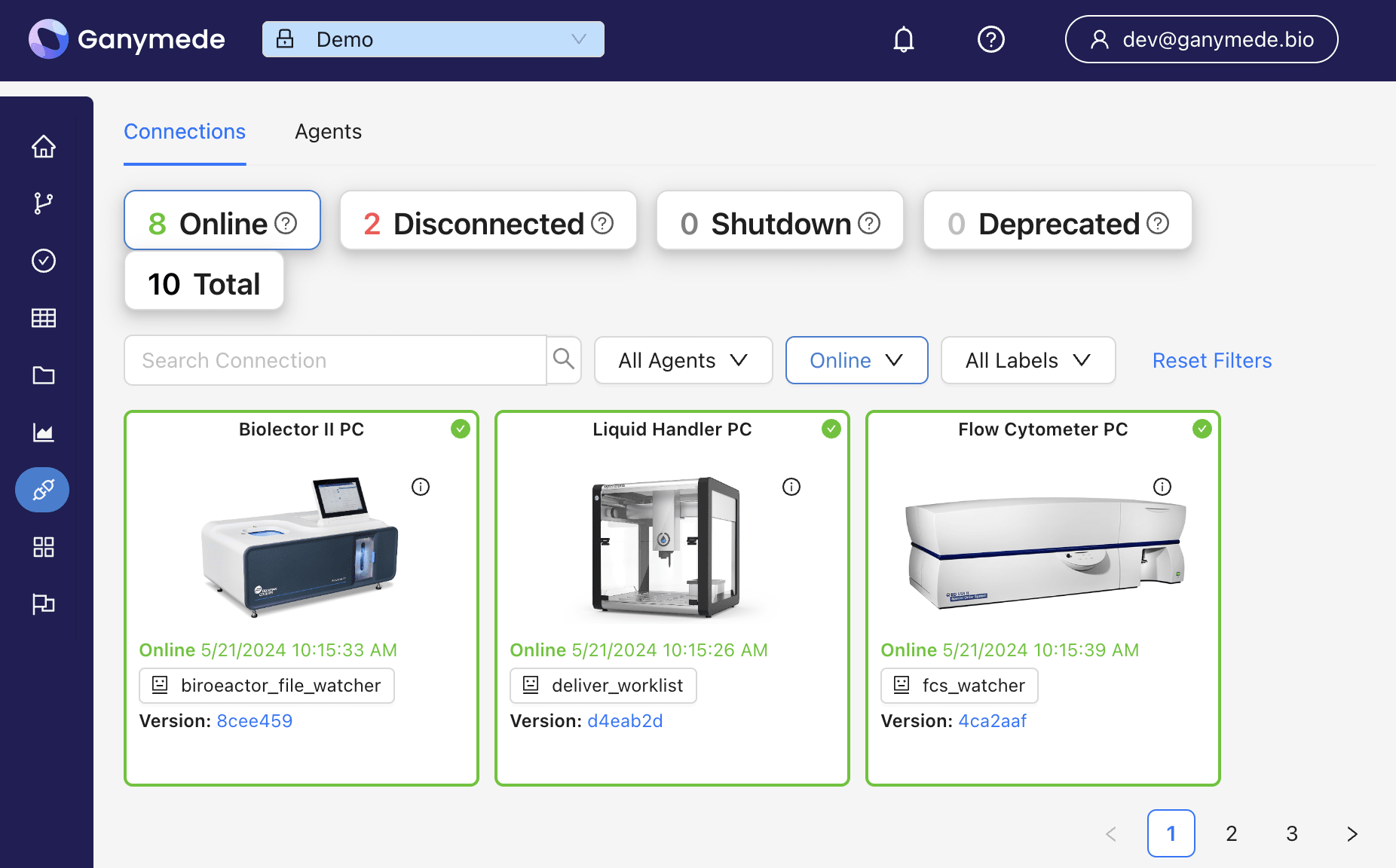
Agents
Agents are locally installed executables for delivering data to and acquiring data from lab instruments. They include a configurable Python component that, if enabled, allows users to remotely manage Agent behavior.
With the Gateway architecture, you can install a single Gateway executable per PC (Host), then add and manage Connections through the Ganymede UI without additional installations.
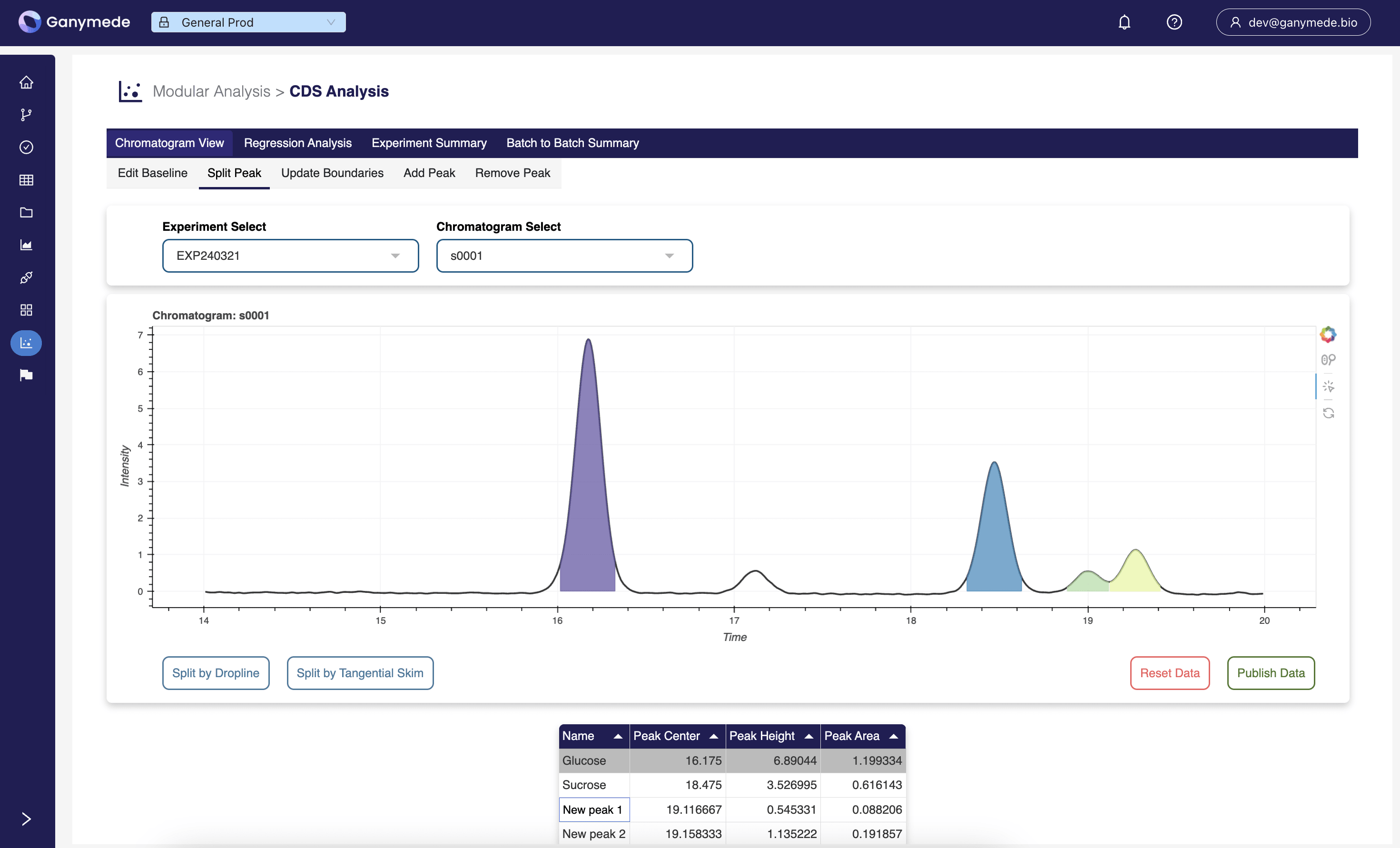
Flows
Flows provide a Python/SQL development environment where code changes are tracked and runtime execution occurs on versioned runtimes, ensuring processing stability and reproducibility.

Nodes within a Flow are equipped with editor notebooks, providing a testing environment for quickly recreating run contexts from prior executions. This enables users to rapidly debug, develop, and deploy pipeline jobs.
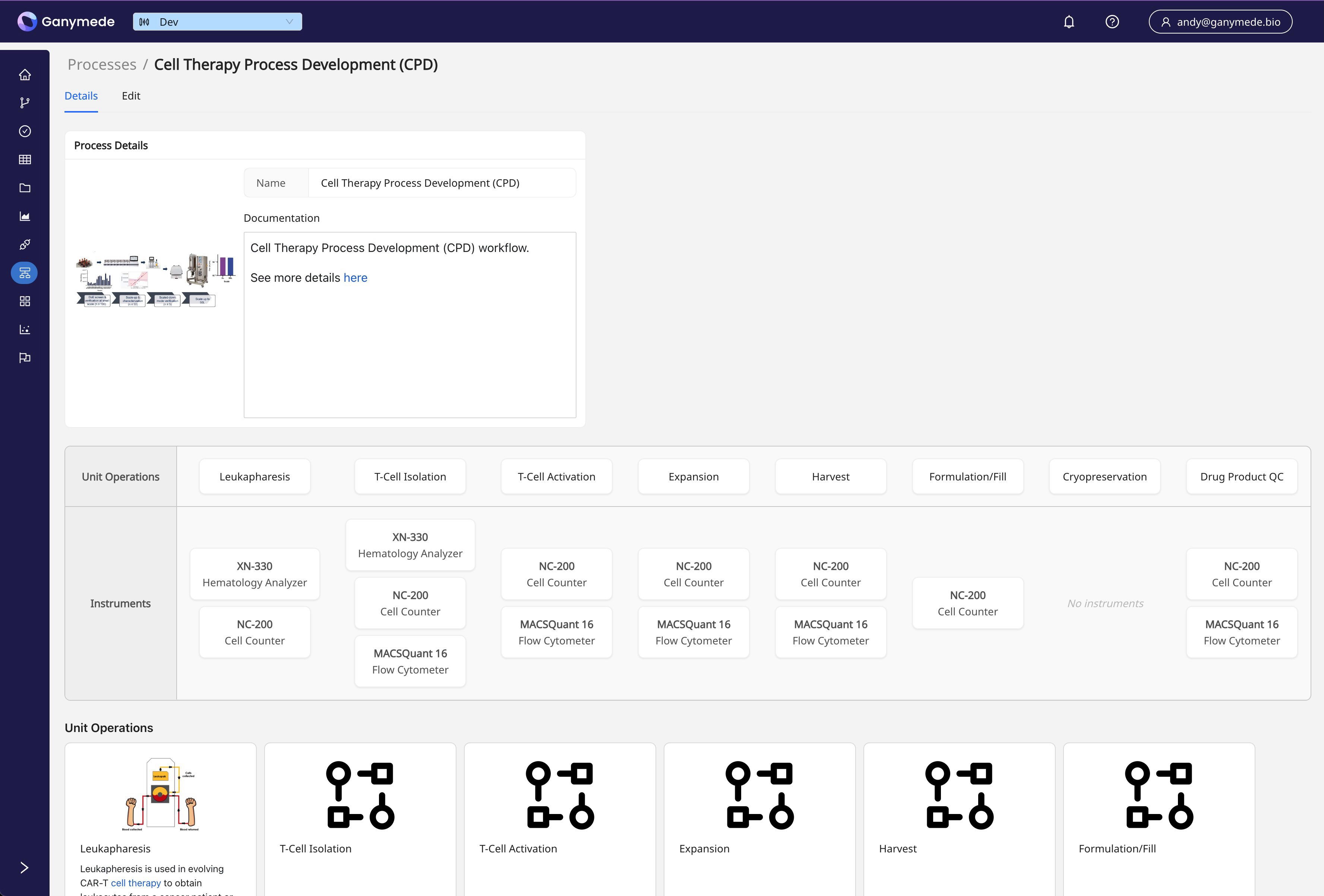
Processes and Unit Operations
Processes and Unit Operations allow users to model and track lab workflows, linking data capture and processing to specific steps in a process.
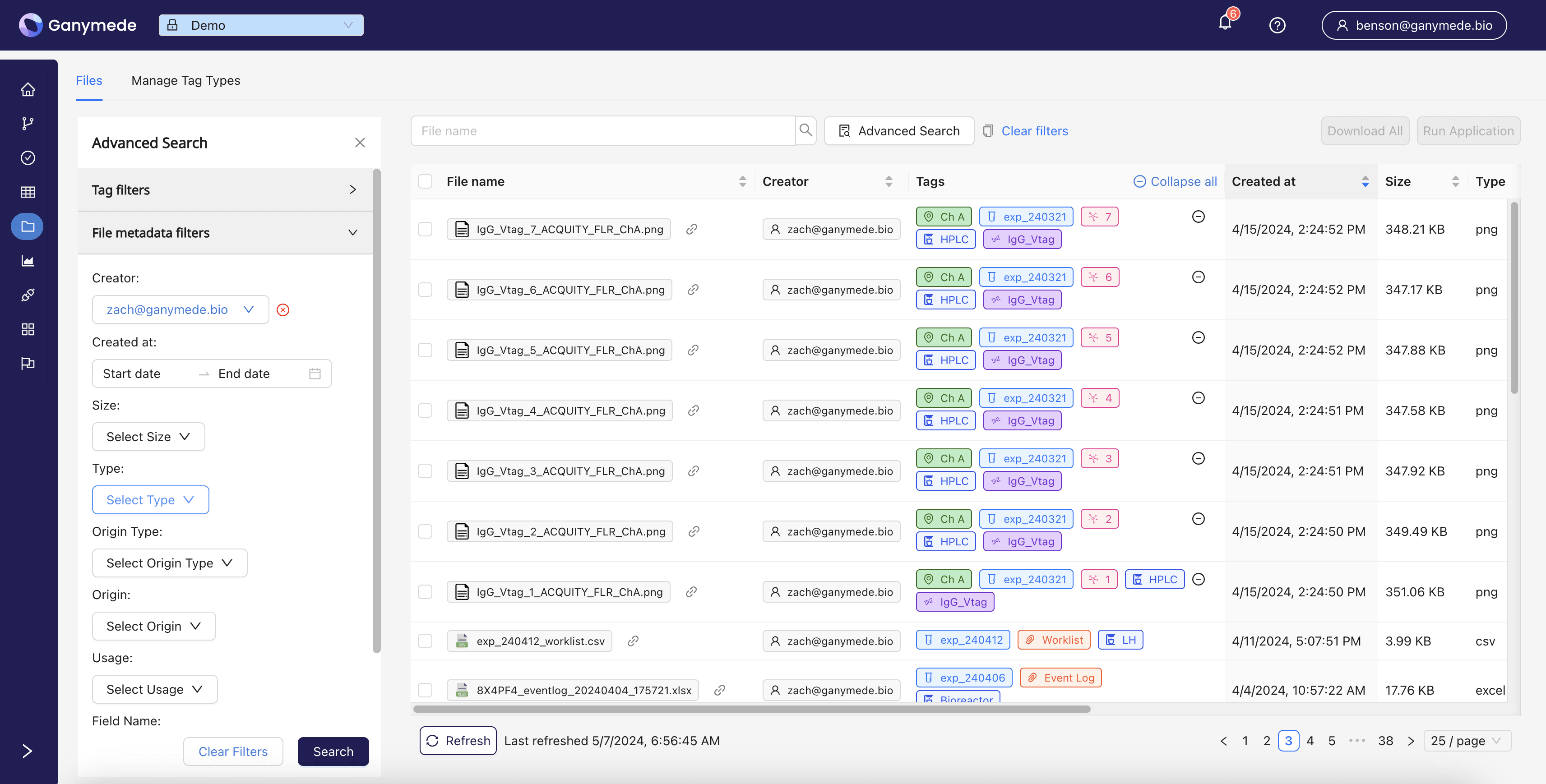
File Browser
The File Browser allows users to filter and select data files by Tags, which Flows and/or Agents, and other file attributes. This allows you to quickly find relevant files by the aspects relevant to you.
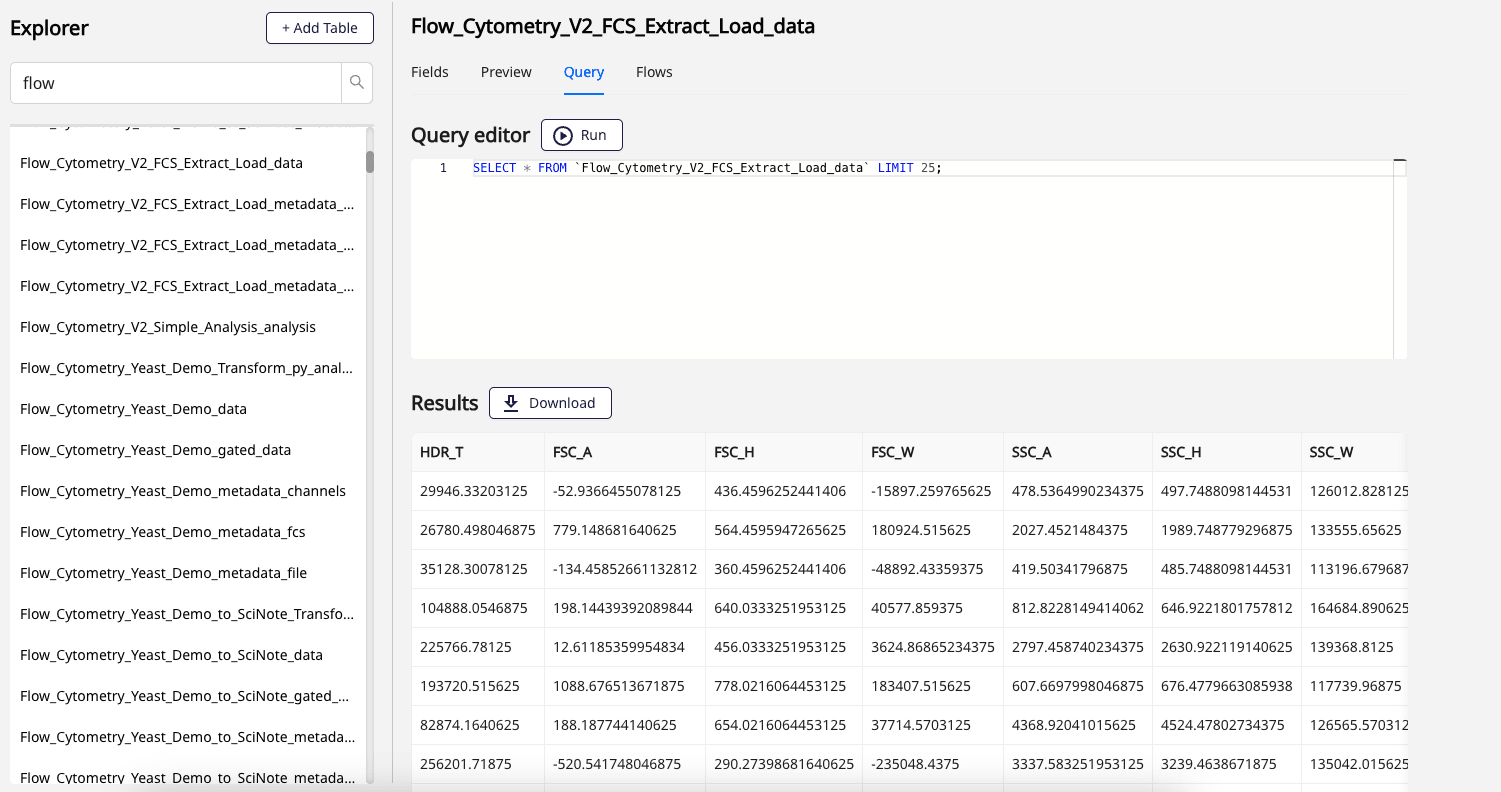
Data Explorer
Data Explorer lets users execute SQL queries on tabular data captured by Agents and Flows.
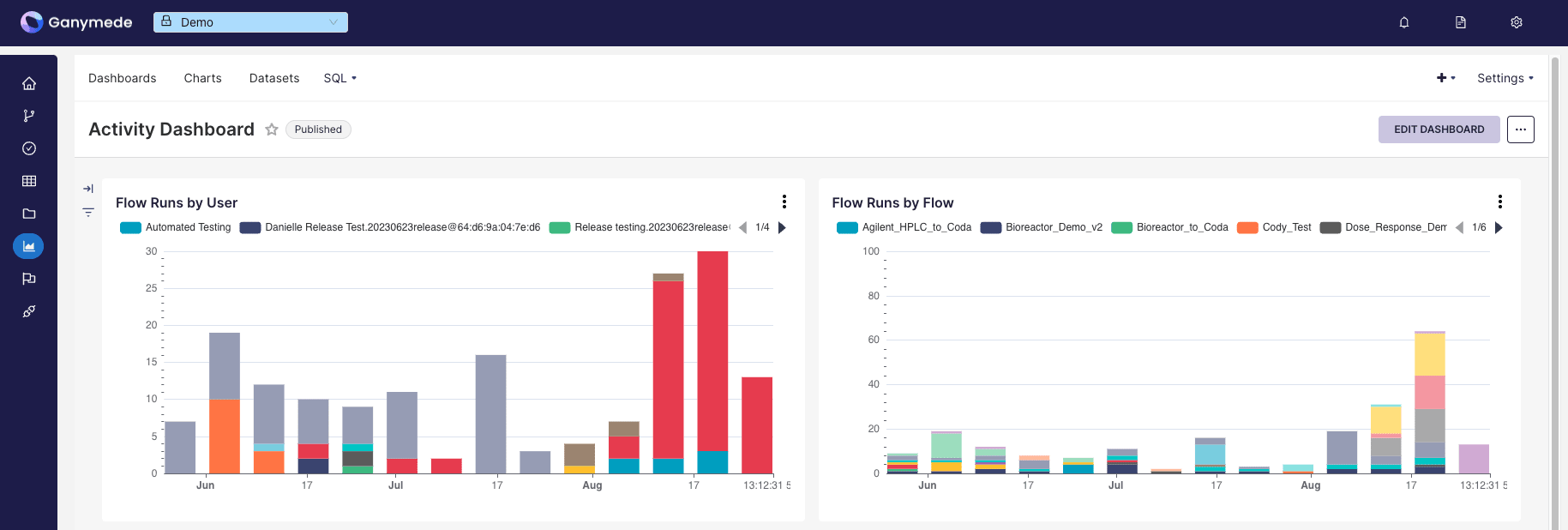
Dashboards
Dashboards offer no-code interfaces for filtering subsets of data, and are updated as underlying data collected is updated.
Virtualization
Virtualization allows users to insert manual processing steps into an automated workflow, offering purpose-built Windows sessions to systematically track manual processing.

Environment Administration
The environment administration panel in Ganymede provides administrators with tools to manage user access and credentials available in the environment.
Getting Started
To get started, you can navigate through a guided tour of your Ganymede environment by clicking on the question mark icon in the top right corner of the app.
Or check out one or more of our Quickstart guides:
- Create an Agent to automatically capture data from lab PCs
- Build a Flow to process structured and unstructured data
- Create a dashboard to visualize data
For administrators, check out our Admin Settings documentation to manage users and environment settings.
For developers, check out our self-managed repo and API setup documentation.
Need Help?
If you need assistance, please reach out to Ganymede Support through the Support page or contact your organization's Ganymede administrator.