Ganymede Concepts
Developers using Ganymede author flows, which are functions comprised of user-editable nodes. Nodes are used to ingest data, perform calculations, and communicate with APIs.
-
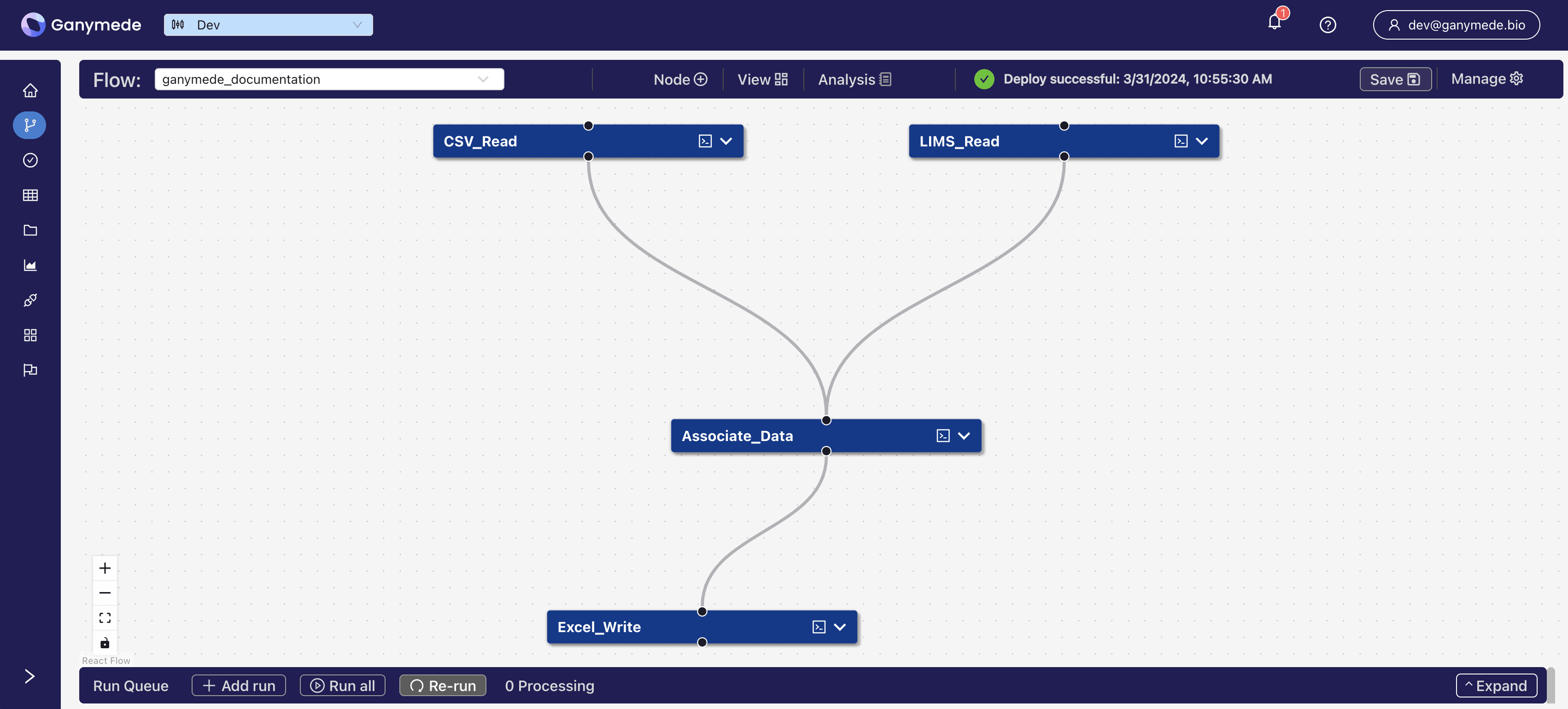
Flow: a set of nodes that processes data; the diagram above shows a flow named ganymede_documentation. Flows are executed top-to-bottom, with edges describing execution dependencies between different nodes.
-
Node: core unit of processing in Ganymede which performs I/O between different systems and the user-defined components of a node. The diagram above contains four nodes: CSV_Read, LIMS_Read, Associate_Data, Excel_Write.
-
Node Attribute: parameters passed into a node. The CSV_Read node above has two node attributes:
csvandresults. -
Table Head: a preview of a table output from the node; in the flow above, example_results is the table head for the CSV_Read node.
-
Agent: locally-installed executable that captures data from external systems and make it available to Ganymede flows. Agents are configured in and monitored from the Connections section of the Ganymede UI.
-
Connection: set of Agents corresponding to the same Connection. For example, you may configure a single Connection for uploading flow cytometry data from different instruments, but each flow cytometer would have its own Agent.
-
Tag: a user-defined label that can be applied to files to facilitate organization and searching. Tags types are configured from the Manage Tag Types view within the Files page in the Ganymede UI. Once configured, these tag types are referenced in user-defined code associated with Agents and Flows.
Each node consists of an Operator and, if customizable, user-defined SQL and/or user-defined Python to enable customization as shown in the conceptual diagram below:

Depending on the node, data may be retrieved from or sent to
- a SQL database
- cloud storage
- third-party API
- flat files
A comprehensive listing of different nodes and their attributes can be found on the Node Overview page
When flows are saved, whether from the flow editor or from a node specific to a notebook, associated code changes are stored in a git repository and deployed to a cloud-native workflow orchestration platform for executing code.